Mercury AI è una nuova soluzione sviluppata da Inception AI (Palo Alto, California, USA) a inizio 2025. Si tratta del primo diffusion-based LLM (dLLM) al mondo, su scala commerciale. La particolarità è un approccio innovativo, completamente diverso dai tradizionali modelli autoregressivi (AR), es. GPT, ecc. Quindi anziché generare token in modo sequenziale, Mercury adotta una tecnica di "denoising iterativo", raffinando in parallelo blocchi di token. La tecnica è comunemente usata per l'ImageAI, mentre per la generazione testuale è una novità e i risultati si sono dimostrati molto interessanti, in particolare lato efficienza. Come riportato sul sito ufficiale inceptionlabs.ai: _<<Mercury is up to 10X faster and more efficient than today’s LLMs while delivering best-in-class quality>>. Sempre sul sito ufficiale, viene riportata questa animazione di confronto con LLM tradizionale autoregressivo, per notare la differente efficienza.

Oltre all'efficienza nell'uso di risorse, il modello è stato migliorato nel tempo (e continua ad esserlo), analogamente agli altri modelli in sviluppo attivo, quindi la qualità delle risposte, i punteggi nei test di benchmark, migliorano.
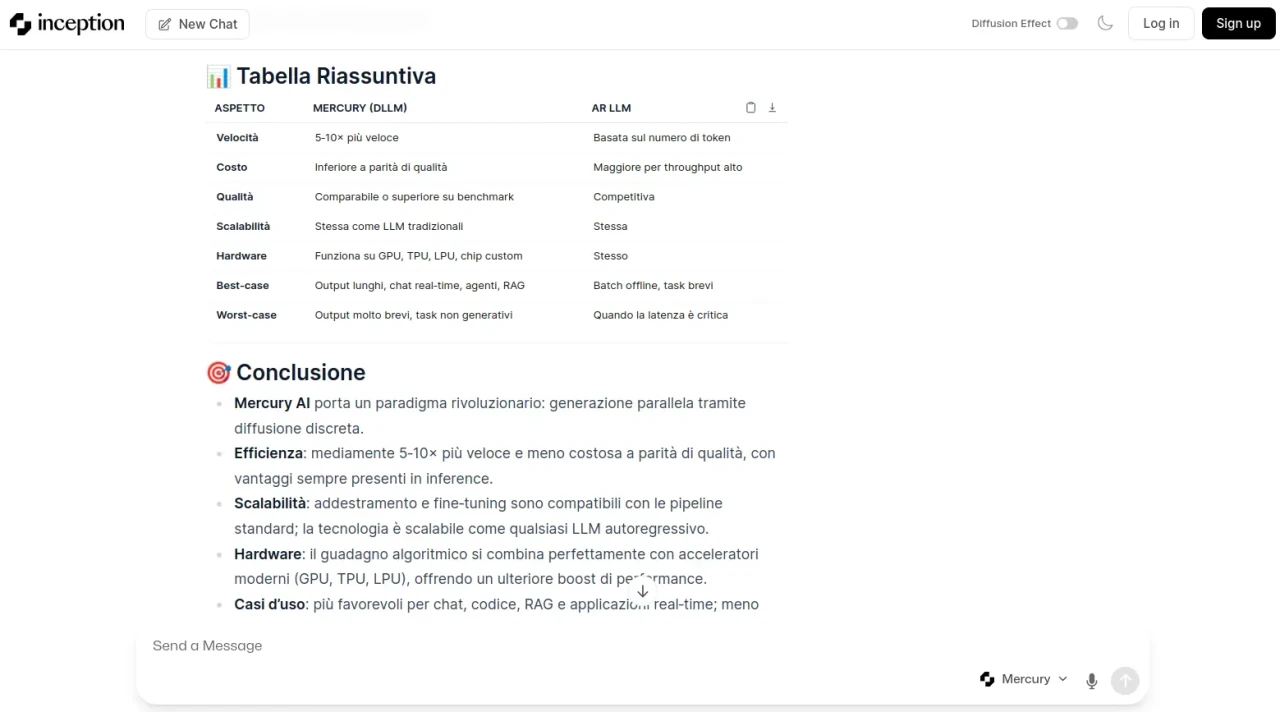
In moltissimi casi la tecnologia adottata da Mercury AI è vantaggiosa, vediamo tuttavia più dettagli per comprendere quando realmente può convenire e quando meno.
✔️ output lunghi (dLLM fino a 10x più veloce)
✔️ app real time (latenza dLLM molto bassa)
✔️ edge AI / on-device (dLLM ottimizzato per risorse limitate)
✔️ RAG (Retrieval-Augmented Generation, trattandosi di documenti lunghi - ricerca web o documento fornito dall'utente - la tecnologia dLLM trae maggiore vantaggio applicativo rispetto ai modelli autoregressivi tradizionali)
❌ task non generativi (es. classificazione, embedding, non sfrutta il parallelismo quindi conviene un LLM tradizionale autoregressivo)
❌ batch elevati ("batch count" significa quante volte l'intero processo viene ripetuto, se il raffinamento richiede batch troppo elevato, la tecnologia dLLM consuma più risorse, diventa meno conveniente)
❌ qualità estrema (se abbiamo bisogno della massima qualità, scegliamo il modello top, modello più grande, tipicamente LLM autoregressivo, quindi senza preoccuparci troppo dell'efficienza)
➖ scalabilità (entrambe le tipologie sono addestrabili e scalabili allo stesso modo: dataset di trilioni di token, operazioni di fine-tuning, ecc)
➖ diversa implementazione hardware (in linea di massima, può funzionare con implementazioni diverse, GPU, TPU, LPU... Vale per entrambi, quindi almeno in linea di massima c'è abbastanza indipendenza software-hardware)
Vista questa panoramica generale, con maggiore focus lato software, vediamo che è teoricamente possibile pensare ad una sinergia hardware + software per sfruttare la massima efficienza! Oggi Mercury, essendo piuttosto recente, è stato testato solamente su GPU (NVIDIA H100); volendo potrebbe essere implementato su hardware più efficiente sviluppato ad-hoc per i campi di IA e machine learning, come TPU di Google e LPU di Groq AI (anche se oggi questo hardware è stato studiato per massimizzare l'efficienza del parallelismo in algoritmi autoregressivi, con i dovuti adattamenti, la nuova implementazione sarebbe teoricamente possibile e sicuramente interessante quantomeno da studiare).
Abbiamo visto come Mercury AI e la tecnologia dLLM possa essere molto promettente, specialmente con le previsioni future di un consumo energetico enorme da parte dell'IA e quindi urgente necessità di trovare soluzioni (oltre all'aumento della disponibilità elettrica, anche lato efficienza, a cui aggiungiamo i casi IA verticale e distillazione).
Mercury AI oggi è accessibile dal sito ufficiale chat.inceptionlabs.ai (gratuito e senza login) oppure anche tramite LMArena.
Come esempio riporto una conversazione che ho avuto con Mercury AI, tramite sito ufficiale, la mia richiesta era proprio... Consigli su come strutturare questo articolo che state leggendo! La risposta è piuttosto lunga, riporto uno screenshot.