Vediamo la situazione a luglio 2025. Il funzionamento della piattaforma è sempre analogo (Battle, Side-by-Side, Direct Chat, Leaderboard). La sezione Leaderboard, aggiornata periodicamente ogni tot giorni, si divide in "Text" (interazioni generali con il chatbot), WebDev, Vision, Search, Copilot, Text-to-Image, Image Edit.
Viene indicato il punteggio ELO per ogni modello, che è funzione della probabilità di vittoria secondo la formula: Ea=1/(1+10^((Rb-Ra)/400)) e analogamente Eb=1/(1+10^((Ra-Rb)/400)), dove:
- Ea = probabilità di vittoria del modello A
- Eb = probabilità di vittoria del modello B
- Ra = punteggio ELO del modello A
- Rb = punteggio ELO del modello B
Vediamo un calcolo di esempio: se gemini-2.5-pro ha punteggio ELO 1462 e deepseek-r1-0528 ha punteggio ELO 1415, la probabilità che gemini-2.5-pro sia superiore a deepseek-r1-0528 è pari a 0,567 = 56,7%; analogamente, dato che la somma delle due probabilità dev'essere unitaria, la probabilità che vinca il secondo modello è pari a 0,433 = 43,3%.
Nota: il punteggio ELO viene assegnato dalle migliaia di interazioni degli utenti, confronto fra un modello e l'altro, sempre secondo la formula sopra descritta.
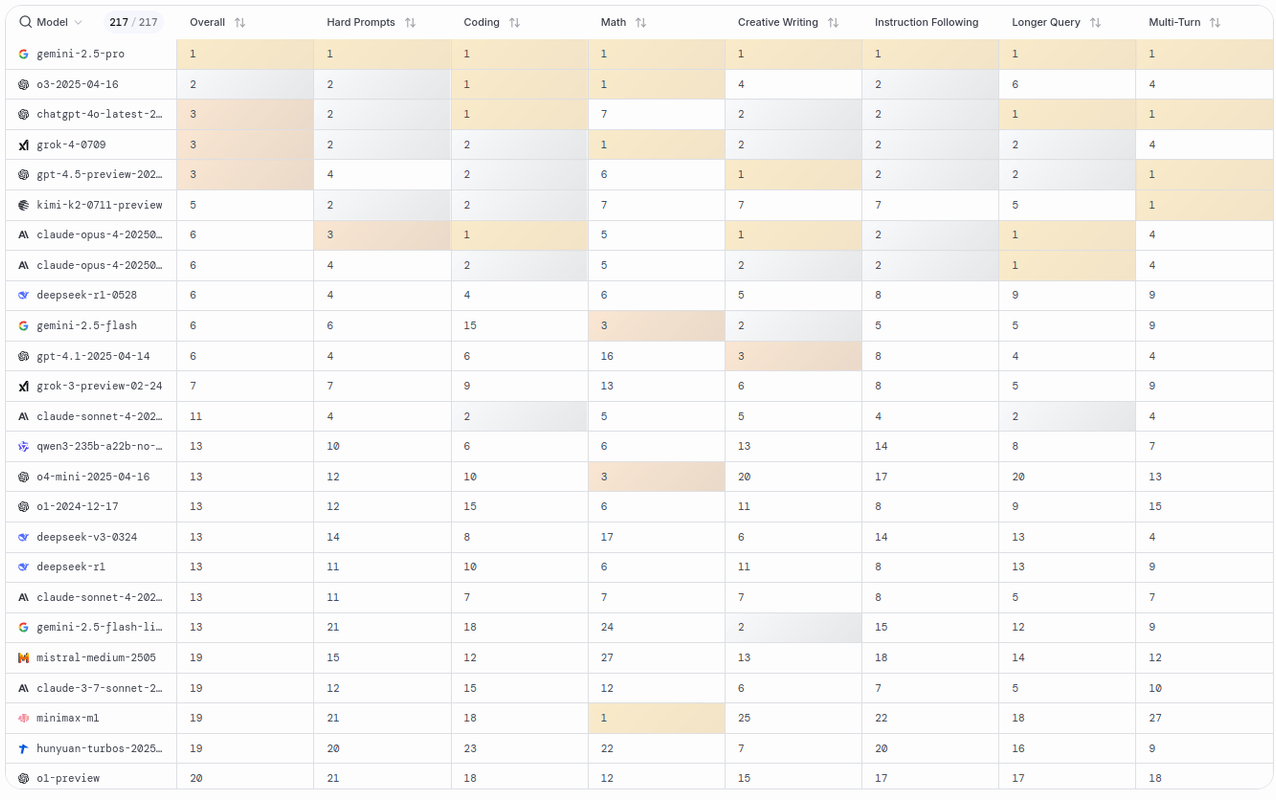
Infine l'interessante sezione Arena Overview che mostra una tabella di risultati, divisa per categorie (oggi, sebbene per uso standard non esageratamente approfondito tutti i top siano circa alla pari come qualità e affidabilità, gemini-2.5-pro ha ottenuto il primo posto in tutto), come vediamo da questo screenshot, situazione a luglio 2025.