Abbiamo parlato di Ollama, per installare modelli IA in locale e di RAG (Retrieval-Augmented Generation), vediamo ora un caso di studio per combinare le due cose assieme. L'obiettivo è fare in modo che un determinato modello, opportunamente istruito, possa dire "ciò che vogliamo noi" (diverso dal fine tuning che avviene in fase di creazione, compilazione del modello, con la RAG invece forniamo accesso a informazioni extra, un nostro documento ecc a modelli già completi, analogamente alla RAG usata dai modelli in Cloud (ChatGPT ecc), che accedono al web real time e tramite web scraping ricavano informazioni che vengono poi elaborate dal modello per la generazione della risposta).
Nello specifico, occorre un file Python, facciamo un'implementazione con embedding semantici (più accurato di una banale ricerca keyword, nel caso fornissimo un contesto di informazioni extra abbastanza lungo e dettagliato). Il codice completo del file Python l'ho generato con l'aiuto di Qwen3-Max.
import ollama
import json
import numpy as np
# Genera embeddings usando Ollama
def get_embedding(text):
response = ollama.embeddings(model='mistral', prompt=text)
return response['embedding']
# Calcola similarità coseno
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Carica e indicizza la knowledge base
knowledge_base = []
with open('knowledge.jsonl', 'r', encoding='utf-8') as f:
for line in f:
item = json.loads(line)
item['embedding'] = get_embedding(item['content'])
knowledge_base.append(item)
# Recupera documenti rilevanti
def retrieve_relevant(query, top_k=3):
query_embedding = get_embedding(query)
similarities = []
for item in knowledge_base:
sim = cosine_similarity(query_embedding, item['embedding'])
similarities.append((sim, item['content']))
similarities.sort(reverse=True, key=lambda x: x[0])
return [content for _, content in similarities[:top_k]]
# RAG completo
def rag_query(question):
contexts = retrieve_relevant(question)
context_text = "\n\n".join(contexts)
prompt = f"""Usa queste informazioni per rispondere:
{context_text}
Domanda: {question}
Risposta:"""
response = ollama.generate(model='mistral', prompt=prompt)
return response['response']
# Interazione dinamica con il terminale
def main():
print("Chatbot RAG con Ollama - Digita 'quit' per uscire")
while True:
user_input = input("\nDomanda: ").strip()
if user_input.lower() in ['quit', 'exit', 'esci']:
print("Arrivederci!")
break
if not user_input:
continue
try:
response = rag_query(user_input)
print(f"\nRisposta:\n{response}")
except Exception as e:
print(f"Errore: {str(e)}")
if __name__ == "__main__":
main()
Abbiamo poi un file knowledge.jsonl (JSON LINES) , con la seguente sintassi di esempio:
{"content": "contenuto_1"}
{"content": "contenuto_2"}
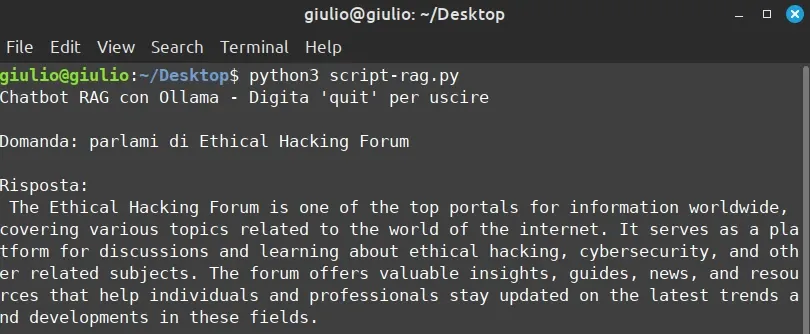
Ora dobbiamo semplicemente avviare il file Python. Chiede di inserire un prompt, poniamo una domanda relativa al contesto che abbiamo usato per istruire il modello. In questo caso vediamo la risposta (nota: si tratta di Mistral 7B, un modello piccolino e mi ha risposto in lingua inglese, chiaramente il risultato è già da considerarsi soddisfacente. La risposta, simpatica, che vediamo nello screenshot che segue, ovviamente dipende dalle info che abbiamo aggiunto nel nostro file knowledge.jsonl 😁