C vs Python: aggiornamenti e ottimizzazioni
Ritorniamo a questo caso di studio, con alcune precisazioni e accortezze importanti da fare. Oltre ad alcune ottimizzazioni già discusse per il linguaggio C (vedi Giulio_M), valutiamo questo:
- linguaggio C: partendo da C_opt e le migliorie aggiunte successivamente, sfruttiamo invece la cosa più importante ovvero le ottimizzazioni di compilazione
- linguaggio Python: possiamo riscrivere meglio il codice, dato che il codice Python standard evidenzia una notevole inefficienza, tuttavia la libreria NumPy ci consente di sostituire il ciclo for con operazioni vettoriali, molto più efficienti, così come alcune ottimizzazioni lato algoritmo concettuale, già fatte con il linguaggio C, come spostare la costante moltiplicativa fuori dal ciclo e calcolarla un'unica volta
Il codice C è quindi il precedente C_opt. Il nuovo codice Python, ottimizzato tramite IA, diventa:
import time
import numpy as np
# Parametri
N = 10**6
a = 0
b = 20
h = (b - a) / N
# Costante precalcolata
const = 1 / np.sqrt(2 * np.pi)
# Funzione vettoriale
def f(x):
return const * np.exp(-x**2 / 2)
# Inizio misurazione del tempo
start = time.time()
# Creazione vettoriale dei punti x
x = np.linspace(a, b, N, endpoint=False) # escludiamo l'estremo destro per il metodo dei rettangoli
# Calcolo dell'integrale (metodo dei rettangoli, vettoriale)
ris = h * np.sum(f(x))
# Fine misurazione del tempo
end = time.time()
# Stampa dei risultati
print("ris =", ris)
print(end - start, "s")
Quindi vediamo ora i risultati di prestazioni, da confrontare solo fra questi e non con i precedenti, dato che questo test è stato eseguito su una macchina diversa:
- nuovo codice Python: tempo di esecuzione medio 0,72 secondi
- linguaggio C "ottimizzato" ma compilato senza ottimizzazioni: tempo di esecuzione medio 0,016 secondi
- linguaggio C con compilazione avanzata (
gcc -O2 -march=native test.c -o test -lm): tempo di esecuzione medio 0,0007 secondi
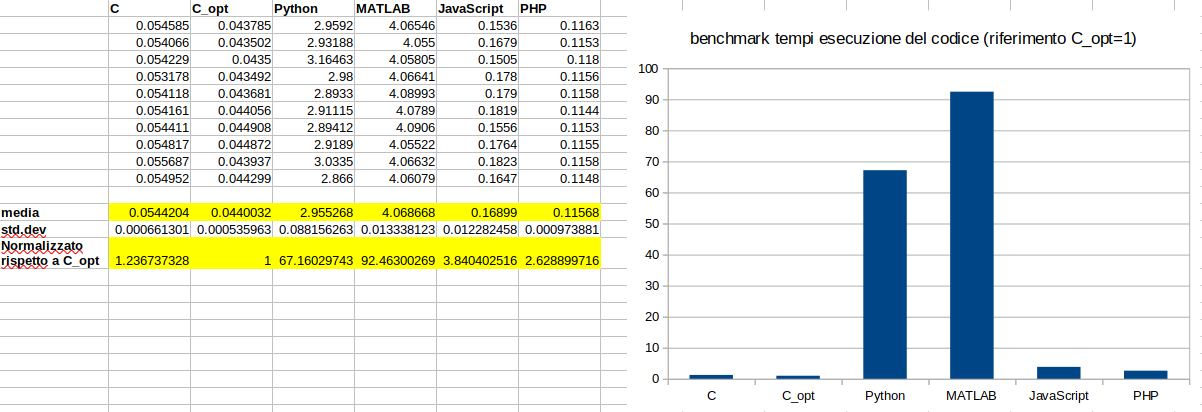
Confronto e analisi dei risultati: quindi il codice C senza ottimizzazioni di compilazione risulta essere 45 volte più veloce di Python ottimizzato (nel precedente benchmark - non consideriamo i valori assoluti trattandosi di un'altra macchina, ma i valori relativi fra i diversi linguaggi - il codice C ottimizzato, ma senza le ottimizzazioni di compilazione, è risultato 67 volte più veloce della versione base di Python). Le ottimizzazioni di compilazione invece spostano il risultato su un'altra scala, 0,72/0,0007 = 1028,5; quindi il linguaggio C compilato tramite ottimizzazioni specifiche del compilatore, raggiunge una velocità 1028,5 volte maggiore rispetto a questo nuovo codice Python ottimizzato. Insomma il linguaggio C mantiene sempre la corona. 👑
Nota: per esecuzioni relativamente veloci, come questa, c'è da dire che ad esempio nel linguaggio Python il caricamento della libreria NumPy e creazione degli array rappresenta una quota non trascurabile rispetto al totale. Se si facessero miliardi di iterazioni, il focus si sposterebbe sul brute-force dell'algoritmo di risoluzione numerica dell'integrale, in questo caso.
Nell'eventualità, trattandosi di un problema piuttosto semplice e "meccanico", il calcolo parallelo migliorerebbe ulteriormente i risultati. In genere, analogamente a quanto detto prima, l'eventuale beneficio diventa significativo se il numero di iterazioni è più elevato.