Avevamo parlato dei robots.txt creativi: il file robots.txt serve per dare istruzioni al crawler, i bot dei motori di ricerca (Google, Bing ecc) che scansionano le pagine web per aggiungerle al proprio indice, eventualmente aggiornarle e determinare i posizionamenti per le varie query di ricerca.
Il file robots.txt "dovrebbe" essere puramente tecnico e funzionale, limitato al massimo, ad esempio la struttura standard di default è questa:
User-agent: *
Disallow:
Alcuni domini di una certa grandezza come google.com, ha senso che abbiano una serie di istruzioni su sottodomini e sezioni da consentire o escludere l'accesso ai bot. Altri siti decidono di scrivere tramite commento le cose più disparate, come appunto abbiamo visto nella discussione robots.txt creativi. Ad esempio tripadvisor.com/robots.txt contiene un annuncio di lavoro, youtube.com/robots.txt contiene un messaggio che gli alieni hanno rimpiazato la razza umana, ecc.
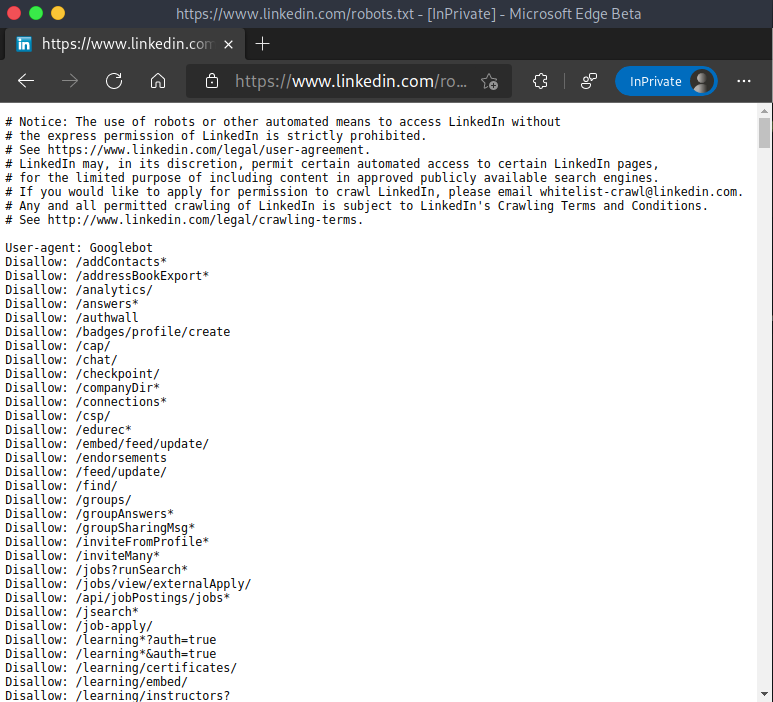
Vediamo il file robots.txt di LinkedIn: onestamente credo sia il robots.txt più lungo che abbia mai visto in vita mia, non so se abbiano senso tutte quelle istruzioni (alcune si potevano accorpare o comunque prevedere un architettura diversa del sito). Oltre alla lunghezza spropositata, compare anche il messaggio "di allerta":
Notice: The use of robots or other automated means to access LinkedIn without the express permission of LinkedIn is strictly prohibited.
Peccato, io che volevo fare una bella scansione con Screaming Frog 😅
È probabile che la ragione sia dovuta al fatto che LinkedIn contiene una serie di informazioni (in pratica, il curriculum completo) ed è diverso da Facebook, Instagram dove in genere viene meno la necessità di impostare "pubblico" un profilo (lo fai solo se lo vuoi fare); su LinkedIn invece offre maggiore visibilità per potenziali opportunità lavorative, contesto quindi un pochino differente.
Per l'anteprima e vederne la lunghezza, ecco il file robots.txt di LinkedIn nella seguente immagine: