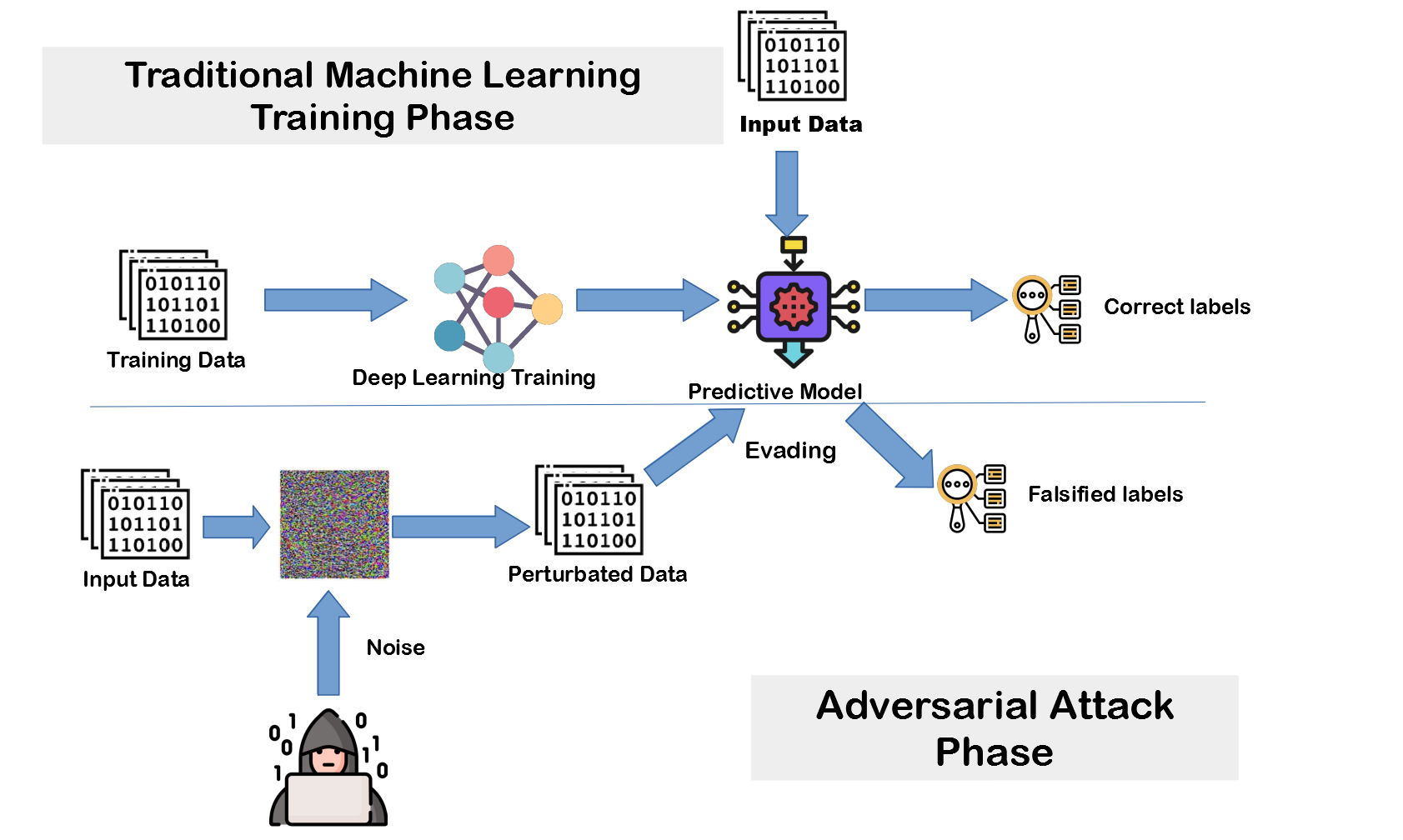
L'Adversarial Machine Learning (apprendimento automatico avversario) non è l'attacco vero e proprio ma un campo che si concentra sullo studio di come i modelli di machine learning possano essere ingannati, manipolati o attaccati da avversari.

Gli avversari in questo contesto possono essere sia umani che algoritmi che cercano di sfruttare le vulnerabilità dei modelli per ottenere forzatamente dei risultati.
I vari tipi di attacchi Adversarial Machine Learning sono:
- Poisoning Attack: dove l'attaccante modifica intenzionalmente un insieme dei dati del database dell'AI, introducendo esempi malevoli o manipolati. L'obiettivo è proprio quello di influenzare il processo di addestramento in modo che l'AI diventi inaccurato o generi risultati indesiderati nell'uso.

- Evasion Attack: in questo caso l'attaccante cerca di manipolare gli esempi di input durante la fase di inferenza in modo che il modello scriva risultati diversi. Questo avviene aggiungendo piccole modifiche malevole (anche con caratteri speciali) agli input che sono impercettibili per gli esseri umani ma possono confondere il modello. In genere sono spesso utilizzati per ingannare i sistemi antivirus o sistemi antispam.

- Extraction Attack: l'attaccante cerca di estrarre informazioni sensibili o dati dal modello di machine learning stesso, sempre lavorando sull'input. Questo può essere fatto utilizzando query mirate o analizzando le sue risposte a diverse domande.
L'obiettivo è ottenere una comprensione dettagliata del funzionamento interno del modello o delle informazioni contenute nei dati di addestramento.

Come ci si può difendere da questi tipi di attacchi? Alcuni approcci potrebbero essere l'ensemble di modelli, cioè combinare le previsioni di diversi modelli in modo da rendere più difficile "l'inganno". Poi chiaramente aggiornamenti costanti, verifica dei dati nel database e continue analisi di sensibilità.